Introduction
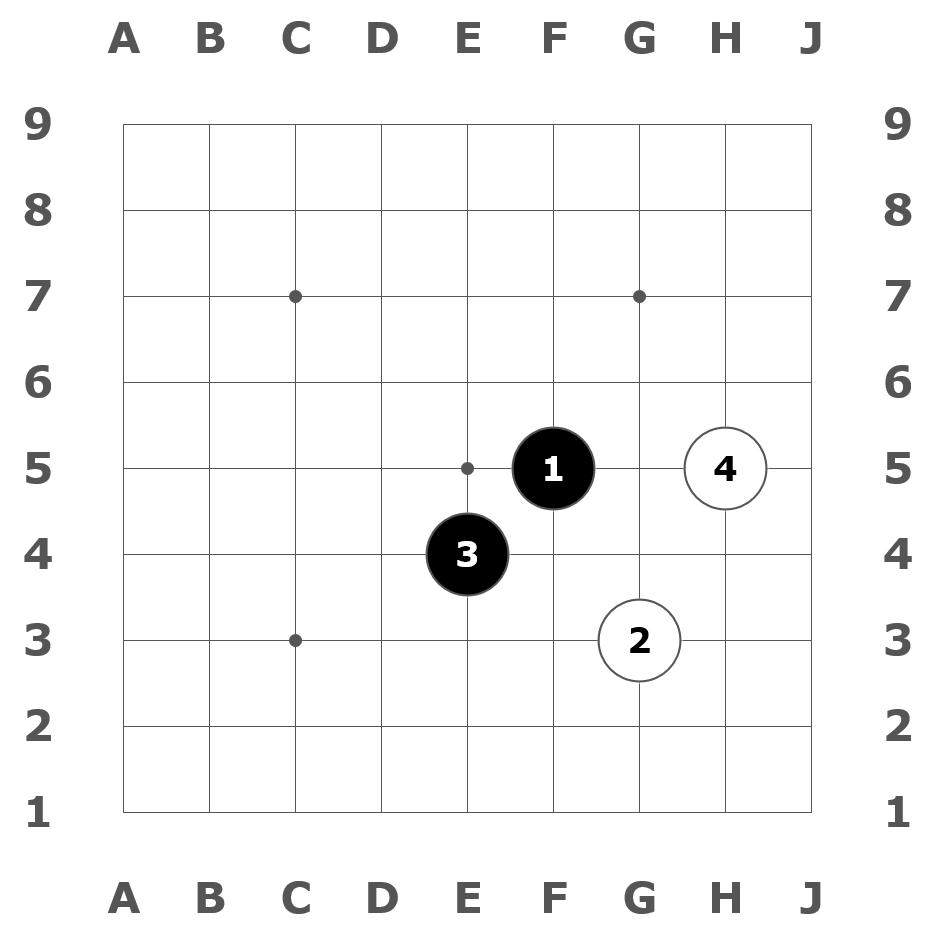
Moves
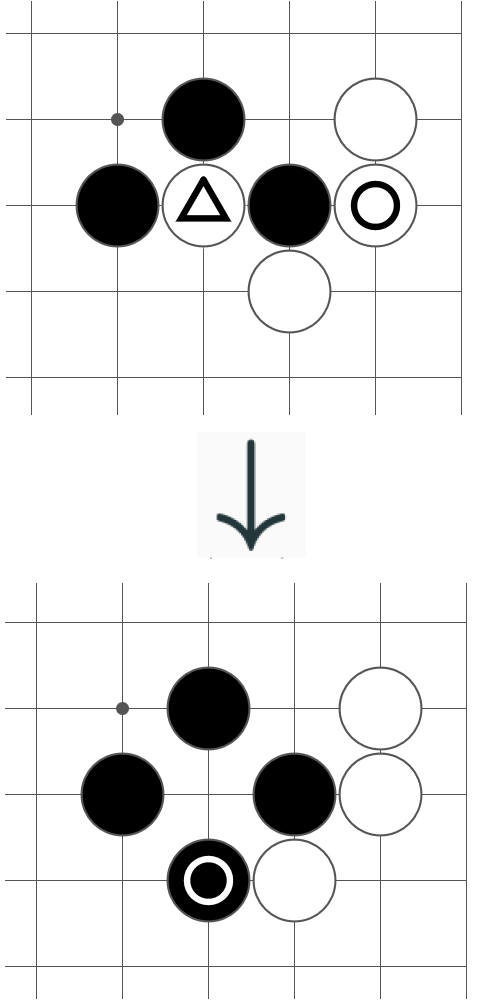
Capture
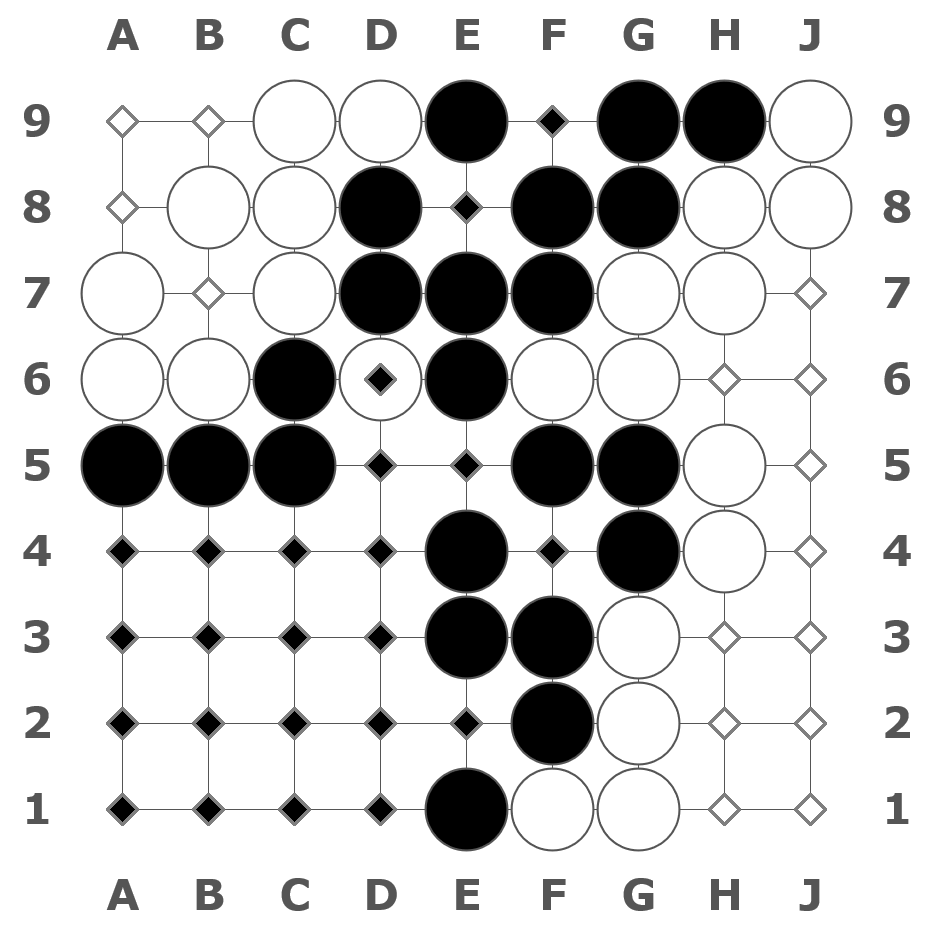
Counting
Go is an ancient 2-player game from East Asia. Its rules are simple, but its enormous strategic depth kept it beyond the capabilities of traditional game-playing computer algorithms for the longest time.
With the development of AlphaGo by DeepMind in 2015, using deep convolutional neural networks, a computer Go program could exceed top human professionals for the first time.
AlphaGo and community-driven reproductions like KataGo have achieved good performance in playing the game. In this thesis, we take on the task of strength estimation, also called skill asssessment.
In this task, we want to look at the competetive performance of a player, meaning past games played by that player, and give them a value, a rating that quantifies their playing strength.
This allows us to compare different players, to see who is better at the game and who is worse. We can also predict who is going to win the next game between two particular competitors and with what chance. Finally, we can use rating numbers to find and match suitable opponents.
My full thesis is available to download here.
The Approach
The usual approach to this problem is to use a rating system based on paired comparisons. We observe the win-loss record of a pool of players. Then we assign a higher rating to the players who win and a lower rating to the players who lose.
The most well-known such system is the Elo system, designed by Arpad Elo for rating Chess players. The Elo system has over time been built upon with more refined rating systems, such as Glicko-2, designed by Mark Glickman. It adds more metrics to the rating besides the rating number. Those are the rating deviation, which indicates the uncertainty of the system about the player's rating, and the volatility, which describes how fast the player's strength is changing.
In this thesis, we will compare our solution to Glicko-2, especially regarding prediction of match outcomes.
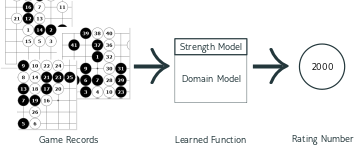
Our solution is a behavioral approach. We look at the behavior of the player, meaning their moves on the board in available full game records. These moves pass through a learned function that computes the rating.
Since learning the game of Go takes a lot of training and computing power, we take an existing neural network domain model to pre-process the input by transfer learning. This model is the neural network of KataGo, a community-driven AlphaGo-style Go playing program. Our strength model, the part that we design and train, is built on top.
The State of the Art
The most noteworthy previous work on this problem with a similar approach was done by Josef Moudřík in 2015 and 2016, around the time of the release of AlphaGo.
In Evaluating Go Game Records for Prediction of Player Attributes, the authors take a player's game records and compute a feature vector of statistics over all the moves. Then they apply a bag of small neural networks to produce a rating, among other targets.
In Determining Player Skill in the Game of Go with Deep Neural Networks, they build a fresh convolutional neural network and train it to predict three classes: weak, intermediate and strong, from a single position.
The key difference between previous works and my thesis is that the previous works either did not yet have access to superhuman Go programs, or did not use the technology to its full potential.
The Architecture
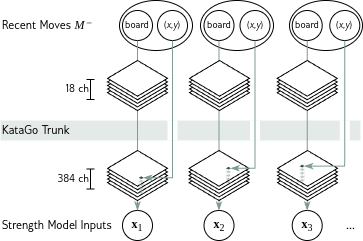
Here we see how we use the KataGo domain model for knowledge extraction to get the inputs for our strength model.
The neural network of KataGo consists of a long trunk, a chain of 18 blocks. At the end of the trunk, the network uses heads which output different predictions, like the policy function and the points lead. This network is trained to find good moves for the MCTS of KataGo, so it contains a lot of domain expertise.
We cut off the head of this network and evaluate the input board positions with the KataGo trunk, which outputs a board-sized internal knowledge representation with 384 channels. We select the feature vector at the position of the input move to get one element for the input set to the strength model.
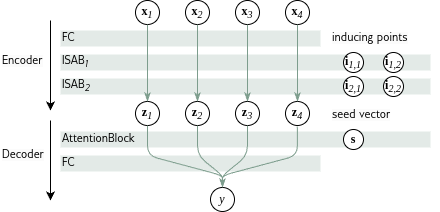
Once we have the inputs for every one of the player's moves, we apply our strength model to the entire set.
The strength model is based on a Set Transformer architecture. Its core is a chain of ISABs, which apply an attention mechanism to the input. Its function is to identify the few informative moves and disregard the obligatory, forced moves.
The inducing points are a fixed-size set that determines the attention queries over the input. The asymptotic number of attention query operations is thus linear in the size of the input, not squared as with self-attention from other Transformer architectures.
The decoder at the end runs a final attention query using a learned seed vector to produce the output rating.
Training
In the course of a single training run, we use the Adam optimizer, a solid and popular choice. It applies gradient-based updates to the training weights in minibatches of 100 samples in each step, 100 steps in each epoch, up to a maximum of 100 epochs. This process stops early after 10 epochs with no improvement.
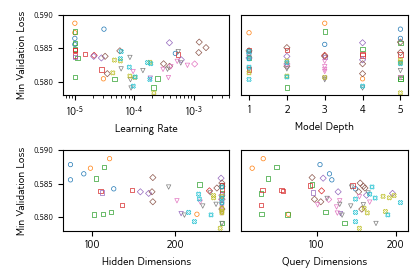
To find the ideal hyperparameters for our model, we run a random search in 5 iterations. Each iteration, we choose 15 random points in hyperparameter space, then the training run that produces the lowest validation error becomes the winner of that iteration. In the next iteration, the 15 random points are narrowed to a closer vicinity around the winner. The winner of the last iteration is our final model.
Results
| Model | Test Set | Exhibition Set | ||
|---|---|---|---|---|
| α | λ | α | λ | |
| Glicko-2 | 69.1% | -0.58 | 64.4% | -0.64 |
| Basic Model | 65.2% | -0.61 | 70.9% | -0.57 |
| Full Model | 68.8% | -0.58 | 73.7% | -0.55 |
This is an excerpt of our results.
We evaluate the different models according to their fitness for match outcome prediction. This is measured in two criteria: α is the percentage of correctly predicted outcomes, while λ is the mean log-likelihood, which also tells us how confident or overconfident the model was.
The first model is Glicko-2, the paired comparison rating system which we also used to generate our training labels. The second is our “Basic Model”, which uses manually selected input features for each move. These input features, like points loss and winrate loss, are precomputed using the KataGo network without transfer learning. Otherwise, it is the same as the full network. The Basic Model is reminiscent of the previous work by Moudřík, see State of the Art above. It is an ablation model with regards to the transfer learning aspect.
The test set is representative of the entire pool. The exhibition set is a set that is favorable to behavioral models because it only contains matches where both participants have a short history of 4 games or less.
Now we can see that our full model is about on par with Glicko-2 in representative cases. It even outperforms Glicko-2 when there are few games on record, because it can utilize the data from the entire game records rather than just wins and losses.
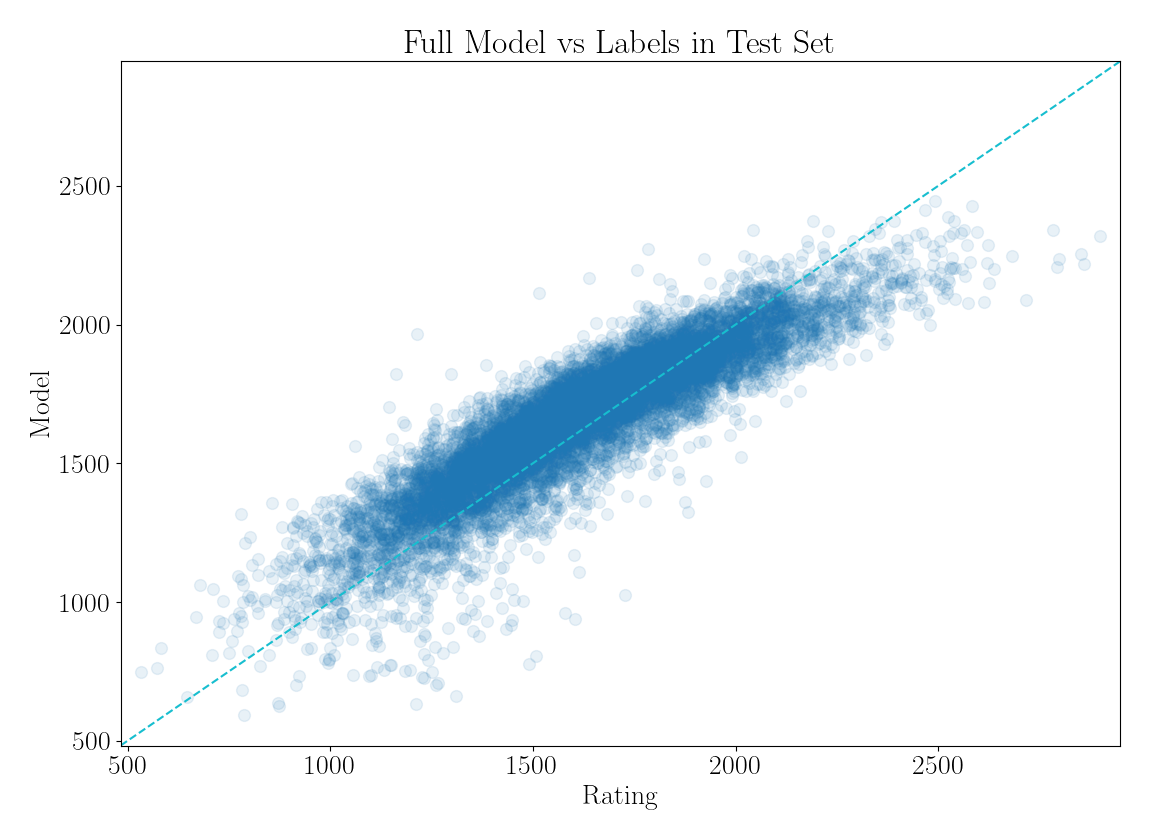
The scatterplot shows the model predictions for player's ratings in the test set, compared to labels based on Glicko-2. We can see that our model is weak at the extremes. It tends to bias towards the mean.
One reason for this is that the training data is representative of the entire pool, and most players are of intermediate strength. It could be improved by sampling training data uniformly over the rating spectrum.
Another potential cause is that we are limited by the domain network output. The KataGo network is not specifically trained to identify weaker players, and it might not be enough to discern the strongest ranks in one shot. This could be improved by including the domain network weights in the training process for the strength model, thus re-adapting it for the new purpose.
These improvements are beyond the scope of this thesis and are left as an avenue for further work.
Applications
Apart from the evaluation of the model as a rating system, we also developed two applications as part of this thesis.
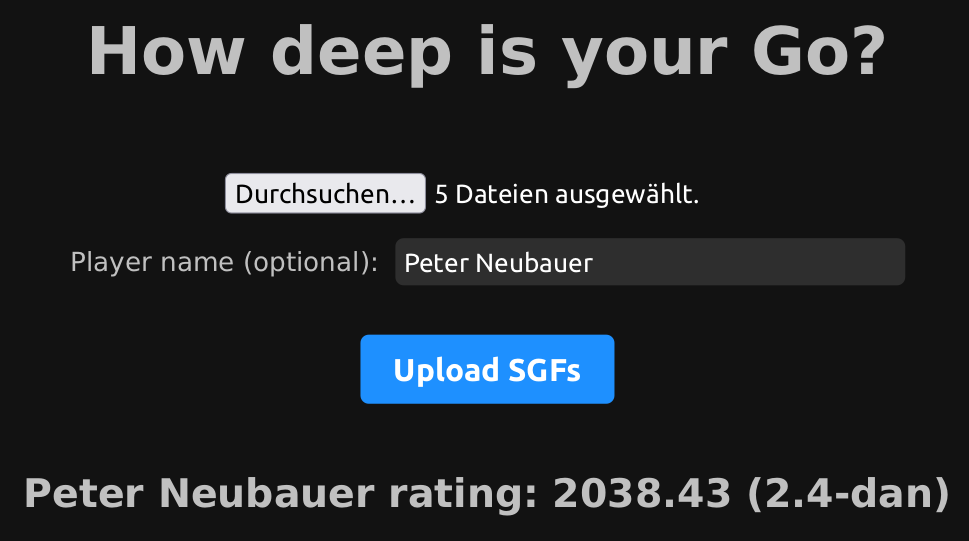
The first application is the website How Deep is your Go, where anyone can upload game records and use the strength model to get an estimate. It was posted to the OGS community and got 1000 visits in the first week.
The second application is a systematic evaluation of 80 problems from the book Tricks in Joseki. The book presents the reader with a problem situation, like the one shown in the image. On the next page, there is a success variation and a failure variation. We put each problem into a whole board context and used the strength model to evaluate both variations, to see what rank the player should be to solve the problem or fail at it.
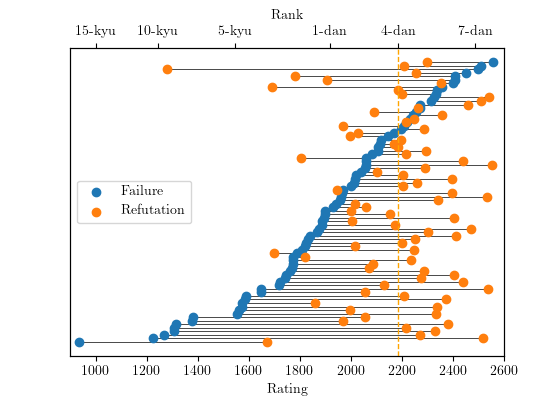
This plot shows all the 80 problems ordered by the rating of the failure variation, represented by the dark point. The horizontal lines connect the problem's failure variation rating to the success variation rating on the same problem.
We can see that a player at 4-dan level, a strong amateur player, should generally be able to solve the problems in this book.
The surprising 18 cases are where the refutation is rated lower than the failure on the same problem. We manually examine each of these cases and conclude that 16 of the the book variations are wrong and the so-called failure variation is actually the correct one. In two cases, the strength model was mistaken.
Conclusion
In this thesis, the author trained a neural network model to perform strength estimation in the game of Go. It can accurately predict a player's rating based on fewer game records than required under traditional paired comparison systems. We reuse domain knowledge by transfer learning.